

洞悉AI爬虫机制,赋能GEO优化抢占流量先机
发布时间:2025-12-22 18:01:38 分类:营销学堂
如果网站想要被更多AI模型所引用,肯定要了解AI抓取的逻辑是什么。AI不是传统的搜索引擎,它不会全网无差别抓取,而是选择性地“理解有价值的知识”。
1.抓取(Crawling)
AI爬虫(如GPTBot、Google-Extended、PerplexityBot)会访问公开网站,但只抓取允许访问的优质内容。所以我们网站的robots.txt,一定要确保可以被AI爬虫所访问,例如可以在robots.txt文档中加入:

2.解析(Understanding)
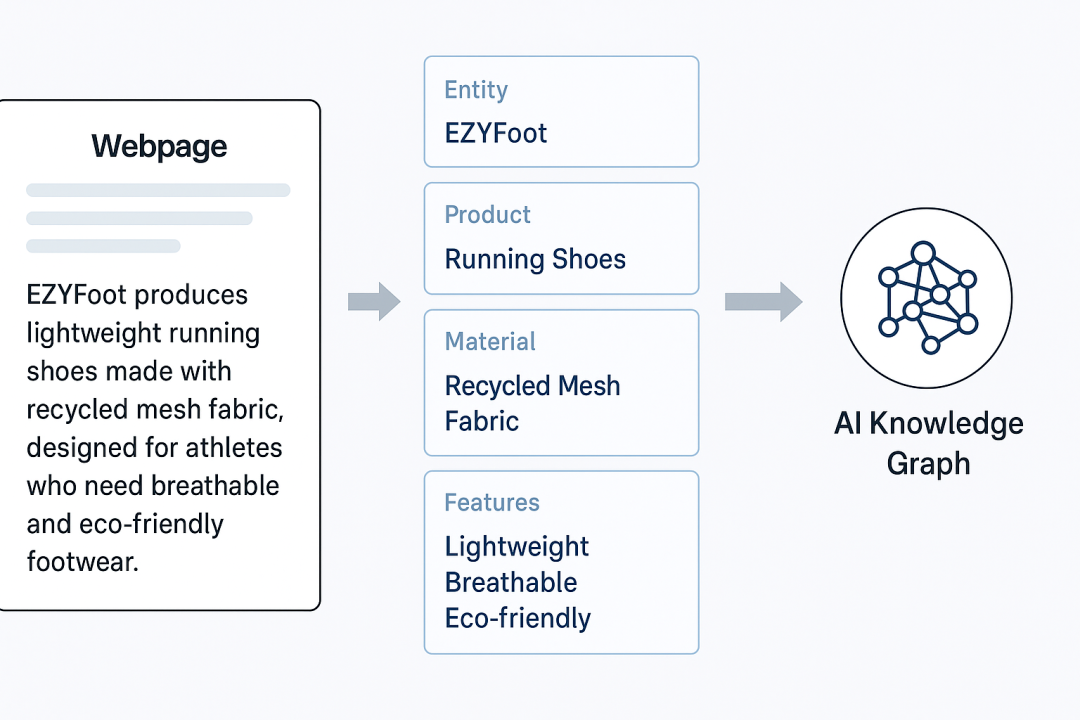
当AI爬虫抓取到网页后,它不会像搜索引擎那样只保存HTML或关键词,而是会理解网页背后的语义信息,将文本转化为可被机器识别的“知识单元”。如:谁、做什么、有什么参数、应用场景是什么。例如:
“EZYFoot produces lightweight running shoes made with recycled mesh fabric, designed for athletes who need breathable and eco-friendly footwear.”
AI模型会这样解析:

3.引用(Referencing)
当用户向AI提问时,模型会执行以下三步:
语义匹配:AI会从“知识数据库”或“最近抓取的网页”中找到语义相关的段落。
重排序与可信度评估:优先选择来源明确(带组织名)、内容结构良好(有标题、FAQ、表格)、权威性高的网站(行业、品牌)
答案生成:AI整合多个来源的段落生成自然语言回答,并在需要时附上引用链接(例如 Perplexity、Gemini、ChatGPT Browse 模式)。
图片来源:Google
那么它跟传统搜索引擎之间的抓取逻辑有什么区别呢,大家看一下我整理的对比表格就一目了然了:
在 AI 问答生态日益成熟的今天,网站的价值不再局限于被用户搜索到,更在于被 AI 优先引用。明白 AI 抓取的 “选稿逻辑”,针对性地优化内容质量、结构与可信度,才能让 GEO 优化发挥实效,让网站在 AI 流量红利中占据先机,成为用户获取信息时的权威信源。